언어공부/python
[Python / ML] sklearn 라이브러리를 이용한 scaling
기싼
2022. 10. 8. 20:11
스케일링 하는 이유
- 데이터간 범위가 다르다면 머신이 동작하면서 오류값이 가장 낮은 곳으로 수렴하는 과정에서 속도 차이가 발생
- 예를 들어 나이, 몸무게, 키 데이터가 있다면 나이와 몸무게는 키 데이터보다 숫자가 작아서 오류 역전파 과정에서 가중치가 크게 변하지 않음 하지만 키 데이터는 숫자가 커서 크게 변함..
- 이를 해결하기 위해 모든 데이터들의 범위를 똑같이 맞춰주는 과정이 scaling
- 분포의 모양을 바꾸는것은 아니다.
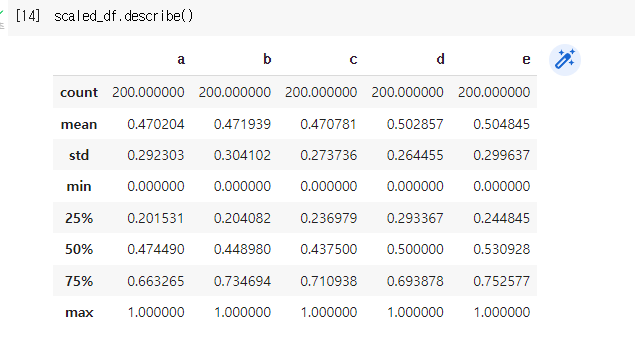
1. Min - Max Scaling

- 수치형 데이터를 0~1 사이로 변경시켜줌
- 언제나 0과 1의 값은 존재하게된다.
- 코드 예시



2. Standard Scaling

- 표준 정규분포화 하여서 평균이 0이고 표준편차가 1이 되도록 scaling을 하는 방법이다.
- z-score 정규화라고도 말한다.
- 코드 예시


