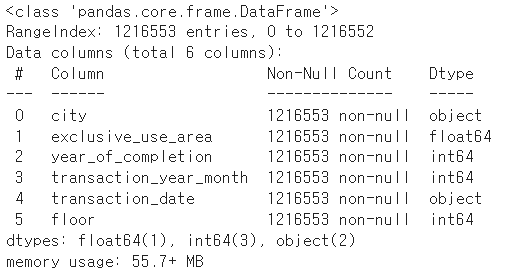
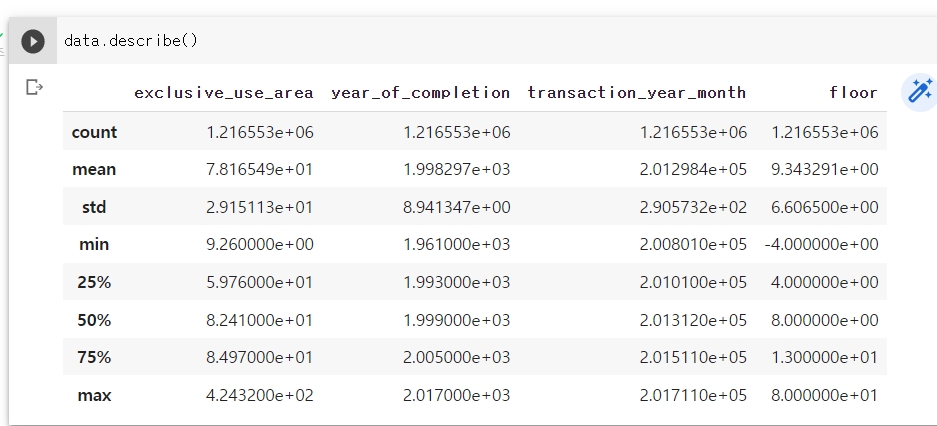
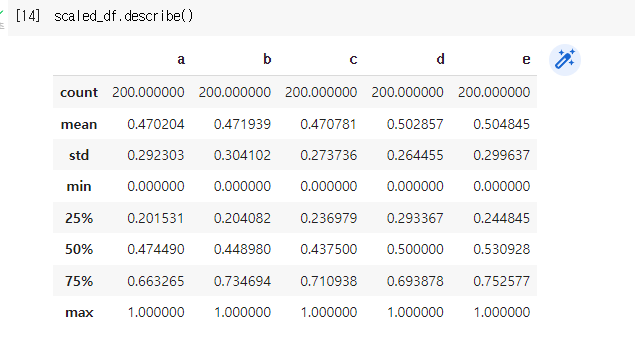
데이터에 null값이 존재할때 즉 데이터 프레임에 빵꾸 나있을때에 그대로 머신에 넣으면 오류가 난다.. ( 아닌가..? 해본적이없다.. )
이를 해결하기위해 우리가 임의로 데이터를 넣자니 안될거같고.. 어떤 방법들이 있는지 알아보자..
일단 아래 나온 방법들이 가장 좋다라는 것은 아니다 언제나 데이터에 따라 머신에 따라 어떤 방법을 써야할지는 엔지니어가 결정해야한다.
pandas로 null값 확인하기
먼저 imputation을 하기전에 null이 있는지부터 확인을 해야한다.
방법은 isna 또는 isnull이 있다. 둘다 같은 함수.. 이름만 다른..
pd.isnull( dataFrame ).sum() 을 통해 결측치의 갯수를 확인 할 수 있다.
pd.isnull 을 통해 True / False로만 구성된 dataFrame생성
sum()을 통해 열별로 계산 ( True +1, False +0 )
sum()을 한번 더 하게 된다면 행으로도 계산하여 데이터 프레임 전체의 null값을 확인할 수 있다.
pd.isna( dataframe ) 을 통해 true/false 데이터프레임 생성sum() 을 통해 열별 합 계산
sum().sum()을 통해 전체 null갯수 확인
Sklearn.impute.Simplelmputer 을 통한 대체
simpleimputer을 통해서는 평균, 최빈, 중앙값등 간단한 대체가 가능하다.
라이브러리 사용을 위해 import
1. 평균값으로 대체 (Mean Imputation)
결측치가 존재하는 변수에서 결측되지 않은 나머지 값들의 평균을 내어 결측치를 대체하는 방법이다.
해당 값으로 대체 시 변수의 평균값이 변하지 않는다는 장점이 있지만, 많은 단점이 존재한다.
strategy 변수에 mean을 줌으로 평균으로 대체하게해줌
2. 중앙값으로 대체 (Median Imputation)
중간값은 데이터 샘플을 개수에 대해서 절반으로 나누는 위치의 값을 말한다.
데이터 샘플의 수가 짝수개일 때에는 중간에 위치한 두 값의 평균을 사용한다.
모든 관측치의 값을 모두 반영하지 않으므로지나치게 작거나 큰 값(이상치)들의 영향을 덜받는다.
3. 최빈값으로 대체 (Most-Frequent Imputation)
최빈값은 가장 많이 나온 값이다.
1. 새로운 값으로 대체 (Substitution)
아예 해당 데이터 대신에 샘플링 되지 않은 다른 데이터에서 값을 가져온다. (그렇다면 validation set에서도 쓰지 않고 아예 버리게 되는 셈인 건가?)
2. Hot deck imputation
다른 변수에서 비슷한 값을 갖는 데이터 중에서 하나를 랜덤 샘플링하여 그 값을 복사해오는 방법. 이 방법은 결측값이 존재하는 변수가 가질 수 있는 값의 범위가 한정되어 있을 때 이점을 갖는다. 또한 random하게 가져온 값이기 때문에 어느 정도 변동성을 더해준다는 점에서 표준오차의 정확도에 어느 정도 기여를 한다는 점이다.
3. Cold deck imputation
Hot deck imputation과 유사하게, 다른 변수에서 비슷한 값을 갖는 데이터 중에서 하나를 골라 그 값으로 결측치를 대체하는 방식이다. 다만 cold deck imputation에서는 비슷한 양상의 데이터 중에서 하나를 랜덤 샘플링하는 것이 아니라 어떠한 규칙 하(예를 들면, k번째 샘플의 값을 취해온다는 등)에서 하나를 선정하는 것이다. 이 경우 hot deck imputation 과정에서 부여되는 random variation이 제거된다.
4. Regression imputation
결측치가 존재하지 않는 변수를 feature로 삼고, 결측치를 채우고자 하는 변수를 target으로 삼아 regression task를 진행하는 것이다.데이터 내의 다른 변수를 기반으로 결측치를 예측하는 것이기 때문에 변수 간 관계를 그대로 보존할 수 있지만 동시에 예측치 간 variability는 보존하지 못한다. (회귀분석을 생각해보면 regression line은 random component가 존재하지 않는다. regression 값 그 자체로 존재한다. )
5. Stochastic regression imputation
regression 방법에 random residual value를 더해서 결측치의 최종 예측값으로 대체하는 방식. regression 방법의 이점을 모두 갖는데다 random component를 갖는 데에서 따르는 이점 또한 갖는다.
6. Interpolation and extrapolation (보간법, 보외법)
같은 대상으로부터 얻은 다른 관측치로부터 결측치 부분을 추정하는 것이다. 이 경우는 longitudinal data의 경우(어린이의 성장 과정을 추적하는 과정에서 얻은 키 데이터라든지 하는 경우)에만 가능할 것이다.
결론
위와 같이 많은 방법들이 있다. 물론 이 방법들로 진행해야 하는것은 없다.
하지만 서로 다른 방법에 따라 결과의 차이는 분명히 나타난다.
간단한 아래의 예시들을 비교해보면
타이타닉에서 나이의 null 값을 나이의 평균으로 넣는방법
타이타닉에서 나이의 null값을 이름 열을 통해서 대략적인 성별을 판단해 성별의 평균 나이로 넣는방법